
ABSTRAK
Identifikasi akurat cacat pada permukaan logam sangat diminati oleh banyak sektor industri, seperti industri otomotif dan kedirgantaraan. Berbeda dengan teknik inspeksi manual konvensional, sistem inspeksi otomatis baru-baru ini menggunakan model pembelajaran mendalam yang dilatih untuk mendeteksi cacat dengan cepat dan tepat. Pengembangan model-model ini sering kali memerlukan kumpulan data gambar yang substansial untuk memperoleh pengetahuan yang memadai tentang fitur cacat dan meningkatkan akurasi prediktifnya. Ketika data terbatas, teknik augmentasi sering digunakan untuk meningkatkan presisi dan akurasi sistem deteksi cacat. Studi ini menguji kinerja prediksi dari dua model deteksi objek, yaitu Faster Region-based Convolutional Neural Network (Faster R-CNN) dan You Only Look Once versi 8 (YOLOv8), untuk mengidentifikasi cacat penyok pada gambar terbatas permukaan kepala silinder besi cor. Set gambar asli berisi 46 gambar dengan 563 penyok. Untuk mengatasi keterbatasan ketersediaan data, teknik augmentasi gambar umum bersama dengan metode salin-tempel diterapkan. Hasil menunjukkan bahwa augmentasi standar meningkatkan akurasi YOLOv8 sebesar 8,00% dan presisi rata-rata (AP) sebesar 3,00%. Di sisi lain, teknik salin-tempel mencapai peningkatan akurasi sebesar 20,00% dan peningkatan AP sebesar 1% hanya dengan 200 penyok sintetis. Hasil ini memberikan dukungan untuk menggunakan strategi penambahan salin-tempel guna meningkatkan kinerja deteksi cacat, dengan kumpulan data terbatas, yang berkontribusi pada identifikasi cacat yang lebih akurat dalam proses pembuatan ulang.
1 Pendahuluan dan Motivasi
Remanufaktur memainkan peran penting dalam mempromosikan keberlanjutan dan membangun ekonomi sirkular. Remanufaktur memperpanjang umur produk yang mendekati akhir masa manfaatnya, dan mengurangi konsumsi material, penggunaan energi, dan limbah [ 1 ]. Tujuan utamanya adalah memulihkan fungsionalitas produk tanpa menimbulkan biaya material dan energi yang umum terjadi pada proses manufaktur awal [ 2 ]. Remanufaktur melibatkan beberapa langkah utama: pembersihan, inspeksi, dan perbaikan inti [ 3 ]. Di antara langkah-langkah tersebut, inspeksi sangat penting karena remanufaktur harus memastikan bahwa produk dikembalikan ke kondisi dan kinerja seperti baru atau lebih baik [ 4 ].
Meskipun inspeksi manual padat karya dan memakan waktu, sangat penting untuk mencapai akurasi tinggi dalam inspeksi [ 5 ]. Dengan mengurangi cacat, meminimalkan biaya pengerjaan ulang, dan memastikan kualitas produk, inspeksi manual meningkatkan profitabilitas produsen, yang pada gilirannya mendapatkan kepercayaan dari pengguna sekunder dengan meyakinkan mereka tentang keandalan dan kinerja. Kemajuan terbaru dalam alat dan teknik inspeksi mendorong tren menuju sistem otomatis menggunakan pembelajaran mesin (ML) dan visi mesin untuk membantu inspektur manusia dalam proses pembuatan ulang. Teknik ML juga telah digunakan secara luas di berbagai domain mulai dari meningkatkan desain produk hingga meminimalkan konsumsi material untuk membantu perusahaan dalam memperoleh solusi berbasis data yang bertujuan untuk memaksimalkan profitabilitas.
Sistem inspeksi otomatis harus menunjukkan keandalan dan kinerja yang sebanding dengan inspektur manusia dalam deteksi cacat. Sistem ini biasanya menggunakan ML, khususnya model pembelajaran mendalam, di bagian belakang untuk mendeteksi dan mengidentifikasi cacat dengan benar. Melatih model pembelajaran mendalam ini pada rangkaian gambar skenario yang beragam dan kaya yang mencakup variasi dalam bentuk, ukuran, dan jenis cacat sangat penting [ 6 ]. Jika tidak, model biasanya gagal dalam mempelajari fitur cacat dan mengidentifikasi cacat dan lokasinya dengan benar. Ketika dihadapkan dengan sejumlah kecil gambar beranotasi, metode augmentasi data dapat diterapkan untuk meningkatkan contoh cacat yang konsisten dengan konteks manufaktur.
Studi ini berfokus pada dua model deteksi objek yang diadopsi secara luas, Faster Region-based Convolutional Neural Network (Faster R-CNN) dan You Only Look Once versi 8 (YOLOv8), untuk deteksi cacat permukaan logam, khususnya penyok, dalam kumpulan data citra industri. Untuk mengatasi keterbatasan ketersediaan data, teknik augmentasi standar dan salin-tempel diterapkan untuk meningkatkan kinerja model deteksi objek dalam mengidentifikasi penyok pada permukaan besi cor. Teknik augmentasi salin-tempel terdiri dari pengambilan contoh cacat—dalam hal ini, penyok—menduplikasinya, lalu menambalnya ke tempat acak di sekitar gambar untuk dipadukan dengan latar belakang, memastikan bahwa cacat tersebut tampak alami bagi mata manusia. Kinerja prediksi augmentasi salin-tempel dibandingkan dengan teknik augmentasi standar, termasuk pembalikan horizontal, pembalikan vertikal, transposisi, dan pemotongan tengah. Metode salin-tempel untuk augmentasi data mengungguli teknik augmentasi standar dengan mencapai presisi rata-rata (AP) dan akurasi yang lebih tinggi. Organisasi naskah yang mendokumentasikan penelitian ini adalah sebagai berikut. Bagian 2 menyajikan hasil penelitian terdahulu yang terkait. Bagian 3 membahas metodologi dan alat bantu. Hasil penelitian disajikan di Bagian 4. Terakhir, Bagian 5 menyimpulkan makalah dengan kemungkinan peluang penelitian di masa mendatang.
2 Tinjauan Pekerjaan Terkait
Ada dua jenis model dalam pendeteksian objek berdasarkan jaringannya: model satu tahap dan dua tahap. Model satu tahap memberikan pendeteksian objek yang cepat tanpa memerlukan langkah awal apa pun, sehingga memanfaatkan waktu respons yang cepat selama proses inferensi. Model dua tahap pertama-tama menghasilkan usulan wilayah suatu objek dan mengklasifikasikannya. Selanjutnya, model tersebut memperkirakan lokasi dan jenis objek berdasarkan fitur yang diekstrak.
Faster R-CNN adalah model dua tahap yang banyak digunakan untuk deteksi objek. Beberapa penelitian menggunakan Faster R-CNN dalam mendeteksi cacat permukaan logam. Shi et al. [ 7 ] menggabungkan modul perhatian blok konvolusional ke dalam tulang punggung Faster R-CNN untuk menangkap fitur-fitur kritis dan menggunakan algoritma pengelompokan k-means untuk menyesuaikan kotak jangkar untuk deteksi cacat pada permukaan baja. Faster R-CNN yang diperluas mencapai presisi rata-rata rata-rata (mAP) 81% dengan kecepatan deteksi 26 bingkai per detik pada dataset NEU-DET. Dalam penelitian lain, bentuk dari metode shading diintegrasikan ke dalam Faster R-CNN untuk meningkatkan ekstraksi fitur cacat dan mencapai mAP 83% pada dataset NEU-DET [ 8 ].
Model satu tahap juga efektif untuk deteksi cacat pada permukaan logam. Di antara model satu tahap tersebut, YOLO, yang diperkenalkan oleh Redmon et al. [ 9 ], dipelajari secara luas dalam literatur. Seiring berjalannya waktu, beberapa model YOLO telah dirilis, dan diskusi komprehensif tentang model YOLO dapat ditemukan di Terven [ 10 ]. Salah satu versi terbaru, YOLOv8 [ 11 ], telah digunakan untuk deteksi cacat pada permukaan logam. Misalnya, Zubayer et al. [ 12 ] menyelidiki kinerja prediksinya dalam mengidentifikasi cacat mikrostruktur seperti retakan, inklusi, dan porositas gas pada sampel baja tahan karat. Mereka melaporkan 96% mAP untuk retakan dan 94% mAP untuk deteksi porositas menggunakan dataset Metal DAM. Menggunakan YOLOv8, studi lain [ 13 ] mencapai akurasi rata-rata 90,9% dan akurasi maksimum 98,5% untuk mendeteksi kategori individual cacat permukaan pada dataset NEU-DET.
Beberapa studi lain berfokus pada peningkatan kemampuan deteksi YOLOv8 dengan memodifikasi arsitekturnya. Liu dan Ye [ 14 ] memperkenalkan YOLO-IMF, yang menggunakan fungsi kerugian yang berbeda untuk mengukur kerugian pada cacat kecil dan berbentuk tidak teratur, untuk mendeteksi lubang jarum, kotoran, kerutan, dan goresan pada permukaan logam. Hasilnya menunjukkan bahwa YOLO-IMF mencapai mAP 1,2% lebih tinggi daripada YOLOv8. Demikian pula, Zhang dan Zhang [ 15 ] memodifikasi jaringan tulang punggung YOLOv8, menghasilkan peningkatan 3,5% dibandingkan YOLOv8 asli pada dataset NEU-DET. Zhou et al. [ 16 ] mempelajari mengidentifikasi tiga cacat pengecoran: penetrasi, permukaan kasar, dan pembengkakan. Mereka meningkatkan kemampuan representasi fitur dari jaringan piramida fitur, menghasilkan mAP 97,3% dibandingkan dengan mAP 92,6% untuk model YOLOv8n. Dalam studi lain, Wang et al. [ 17 ] memodifikasi tulang punggung YOLOv8 untuk meningkatkan kemampuan ekstraksi fiturnya, menunjukkan peningkatan mAP sebesar 3,25% dibandingkan YOLOv8n.
Meskipun model YOLO kuat dalam tugas deteksi cacat pada permukaan logam, kinerjanya biasanya didorong oleh data [ 6 ]. Secara umum, ada tren bahwa lebih banyak data memberikan model yang lebih baik untuk tugas ini. Namun, mendapatkan data berlabel dalam jumlah besar tidak selalu memungkinkan. Dengan tidak adanya kumpulan data besar yang dianotasi, teknik augmentasi data salin-tempel dapat membantu meningkatkan hasil dengan memberikan pengetahuan tambahan untuk dipelajari oleh model deteksi. Selain itu, teknik ini dapat mensimulasikan beragam skenario di mana objek mungkin ada, yang memungkinkan model ML menyesuaikan diri dengan berbagai situasi [ 18 ]. Teknik salin-tempel memotong objek dan menempelkannya pada latar belakang acak sehingga objek yang dimasukkan tampak alami bagi pengamat manusia [ 19 ]. Teknik ini telah diterapkan dalam berbagai pengaturan, seperti dalam sistem pembayaran otomatis di toko dan supermarket [ 20 ] dan deteksi tanda tangan tulisan tangan [ 21 ], dan telah menunjukkan peningkatan dalam kinerja deteksi. Misalnya, teknik salin-tempel dengan teknik penambahan data tradisional (rotasi, pembalikan, dll.) menghasilkan peningkatan mAP sebesar 21% untuk kumpulan data GMU (kumpulan data pemandangan dapur) [ 19 ].
Singkatnya, karena kinerjanya yang tinggi dalam memprediksi, model YOLO sebagian besar digunakan untuk mendeteksi cacat. Oleh karena itu, kami memilih YOLOv8 sebagai model deteksi objek satu tahap dan Faster R-CNN sebagai model deteksi objek dua tahap yang umum digunakan. Kami mengevaluasi kinerjanya pada kumpulan data industri remanufaktur. Mengingat terbatasnya jumlah gambar beranotasi untuk cacat penyok dalam kumpulan data, metode salin-tempel dan penambahan data tradisional digunakan untuk memeriksa dampak teknik peningkatan data pada kinerja prediksi model.
3 Metodologi
Bagian ini menguraikan tinjauan umum dari dua algoritme yang dipilih, pendekatan augmentasi, pengaturan eksperimen, dan metrik kinerja yang digunakan untuk mengevaluasi kinerja prediksi algoritme. Pertama, Bagian 3.1 menyajikan detail kumpulan data, termasuk bagaimana data diperoleh dan diberi label. Bagian 3.2 dan 3.3 menjelaskan arsitektur model, Faster R-CNN dan YOLOv8s, masing-masing. Bagian 3.4 menjelaskan teknik augmentasi dan bagaimana teknik tersebut diimplementasikan. Kemudian, Bagian 3.5 menjelaskan praproses data dan pengaturan eksperimen. Terakhir, di Bagian 3.6 , metrik kinerja untuk menilai efektivitas model didefinisikan.
3.1 Kumpulan Data
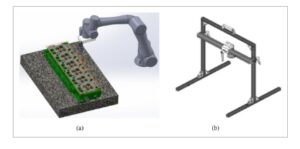
Dua metodologi unik digunakan untuk menangkap gambar penyok yang ditemukan pada permukaan besi cor yang penting untuk proses pembuatan ulang kepala silinder. Yang pertama, disebut di sini sebagai metode pengumpulan laboratorium, dilakukan di lingkungan laboratorium terkendali di Iowa State University menggunakan satu set kepala silinder aktual yang disediakan oleh John Deere Reman. Sistem cobot dan gantry otomatis ditunjukkan pada Gambar 1 , yang dikembangkan dan diimplementasikan untuk memasang dan menggerakkan kamera. Kamera pemindaian area (Basler ace 3088–16 g) yang dilengkapi dengan lensa seri Edmund Optics 8 mm HP menangkap gambar dengan jarak kerja 100 mm dan pengaturan apertur f/4. Kamera menggunakan sensor format Sony IMX178LLJ-C 1/1.8″ dengan resolusi 3088 x 2064 piksel. Gambar ditangkap di titik tengah setiap lokasi kotak grid, seperti yang ditunjukkan pada Gambar 1a . Meskipun penelitian yang sedang berlangsung membahas kontrol optimal berbagai faktor akuisisi, seperti pencahayaan [ 22 ], investigasi ini menggunakan pencahayaan sekitar dengan pengaturan nilai pencahayaan tetap. Pendekatan kedua yang kurang terkontrol digunakan dalam lingkungan toko remanufaktur untuk menangkap gambar menggunakan sistem gantry sederhana (Gambar 1b ) dengan kamera SLR konvensional yang memiliki resolusi 2592 x 1944 piksel. Pendekatan ini memiliki sedikit kontrol atas faktor-faktor yang akan memengaruhi kualitas gambar tetapi diperlukan dalam pengaturan ini untuk menyediakan sejumlah gambar cacat tambahan yang memadai untuk upaya pelatihan model. Gambar yang diambil dalam dua pengaturan ini digabungkan untuk membuat kumpulan data terkonsolidasi. Tim inspeksi menyusun kumpulan data 46 gambar dengan penyok, 563 di antaranya adalah penyok unik. Cacat dan lokasinya diberi anotasi secara manual untuk pelabelan gambar menggunakan “labelimg,” perangkat lunak pelabelan sumber terbuka. Tiga inspektur memberi label gambar yang sama secara kolaboratif untuk pelabelan berurutan guna mengurangi kesalahan dan bias pelabelan. Inspektur berikutnya akan memeriksa dan menyesuaikan label yang ditetapkan oleh inspektur sebelumnya. Pertemuan dijadwalkan untuk menyelesaikan perselisihan di antara para inspektur sehingga konsensus dapat dicapai mengenai jenis dan posisi setiap cacat. Iterasi proses pelabelan dilakukan sampai semua inspektur mencapai kesepakatan mengenai anotasi [ 23 ].
GAMBAR 1
Buka di penampil gambar
Presentasi PowerPoint
Contoh peralatan akuisisi gambar yang digunakan dalam penelitian ini: (a) kamera pemindai area yang dipasang cobot, (b) rig gantry kamera pemindai area mandiri.
3.2 R-CNN yang lebih cepat
Faster R-CNN dapat memanfaatkan peta fitur konvolusional yang mendasari pendahulunya, detektor berbasis kawasan R-CNN dan Fast R-CNN, untuk proposal kawasan yang berisi objek dengan menambahkan Region Proposal Network (RPN). Dengan demikian, RPN dibangun dengan menambahkan satu lapisan konvolusional lagi ke jaringan ekstraksi fitur, khususnya CNN yang telah dilatih sebelumnya. Akibatnya, RPN mengubah detektor berbasis kawasan menjadi jaringan konvolusional penuh yang dapat dilatih dari awal untuk menghasilkan proposal deteksi. Bahan dasar Faster R-CNN adalah sebagai berikut: (1) RPN: Jaringan yang berbagi fitur konvolusional gambar penuh dengan jaringan deteksi objek, sehingga memungkinkan RPN untuk menghasilkan proposal kawasan dengan menggeser peta fitur konvolusional. (2) Detektor Fast R-CNN: Detektor ini memprediksi kategori objek sebenarnya, berbagi lapisan konvolusional dengan RPN. Bahasa Indonesia: Setelah RPN menghasilkan proposal wilayah, hasil prediksi akhir diperoleh menggunakan penggabungan Region of Interest (ROI), pengklasifikasi hulu, dan regresor kotak pembatas. Pendekatan RPN ini menawarkan keuntungan untuk menghindari metode yang membutuhkan komputasi mahal seperti pencarian selektif. RPN, yang menggunakan kotak jangkar, membuat proposal wilayah yang mencakup berbagai ukuran dan rasio aspek [ 23 , 24 ]. Dalam studi ini, kami menggunakan Faster R-CNN dengan ResNet101 sebagai tulang punggungnya. ResNet101, jaringan residual dalam dengan 101 lapisan, meningkatkan ekstraksi fitur dengan menggunakan koneksi residual untuk mengurangi masalah gradien yang menghilang. Arsitektur ini meningkatkan akurasi deteksi objek sambil mempertahankan efisiensi komputasi.
3.3 YOLOv8
Konsep dasar yang mendasari YOLO adalah untuk mempartisi gambar ke dalam grid dan kemudian setiap sel grid menentukan kotak pembatas dan kelas untuk objek di dalam batasnya, alias, identifikasi objek berbasis grid. YOLOv8 adalah perkembangan dari arsitektur YOLO yang dibangun dari kekuatan pendahulunya untuk mengatasi beberapa kekurangan mereka. Ini juga mendukung teknik yang sama untuk identifikasi objek berbasis grid dengan kemajuan dalam akurasi, kecepatan, dan fleksibilitas. Namun, sebagian besar struktur dalam YOLOv8 biasanya dibentuk oleh jaringan saraf utama, yang akan sering dibangun pada arsitektur populer seperti Darknet atau CSPDarknet untuk menangani tugas ekstraksi fitur dari gambar input. Setelah itu, lapisan tambahan akan membuat prediksi tentang kotak pembatas dan kemungkinan kelas yang berbeda. Kemampuan ekstra dalam ekstraksi fitur disediakan dengan bantuan modul terintegrasi yang kuat di YOLOv8, seperti Path Aggregration Network (PANet), Spatial Attention Module (SAM), dan PANet-SAM, untuk meningkatkan deteksi objek. YOLOv8 dirilis dengan lima varian berbeda berdasarkan jumlah parameter: nano (n), kecil (s), sedang (m), besar (l), dan ekstra besar (x) [ 11 ]. Dalam penelitian ini, kami menggunakan varian kecil YOLOv8 (YOLOv8s) karena menyeimbangkan akurasi dan kecepatan sambil membutuhkan lebih sedikit sumber daya komputasi.
3.4 Penambahan Kumpulan Data
Bagian ini menguraikan strategi penambahan untuk meningkatkan kinerja deteksi objek dalam situasi di mana kumpulan data terbatas mencakup gambar berkualitas rendah, keburaman, dan kondisi pencahayaan yang berfluktuasi. Metode penambahan data hanya diterapkan pada set pelatihan. Sebaliknya, set pengujian tetap konstan selama proses ini, memastikan evaluasi kinerja model yang konsisten.
3.4.1 Penambahan Data Standar
Citra penyok dalam set pelatihan diperbesar dengan menggunakan empat teknik pembesaran: (i) pembalikan horizontal, (ii) pembalikan vertikal, (iii) transposisi, dan (iv) pemotongan tengah. Teknik pembesaran ini diterapkan secara individual dan dalam semua kemungkinan kombinasi keduanya untuk meningkatkan set data asli sepuluh kali lipat. Berdasarkan strategi ini, setiap citra penyok dalam set pelatihan asli mengalami pembesaran 10 kali, dan satu set citra baru dibuat dengan beragam orientasi, perspektif, dan ukuran. Tidak ada pembesaran berbasis warna yang diterapkan karena citra yang diambil adalah monokrom.
3.4.2 Penambahan Data Dengan Copy-Paste Dents
Metode yang kami usulkan menggunakan bercak penyok yang diekstrak dari set pelatihan untuk menghasilkan objek penyok tambahan dalam gambar. Untuk mencapai hal ini, objek penyok yang ada (yaitu, bercak) dipilih yang cocok dengan warna latar belakang gambar dalam set pelatihan dan diintegrasikan dengan mulus ke dalam area tempat penyok diantisipasi dengan menyalin dan menempel gambar cacat. Saat menerapkan augmentasi salin-tempel, pemilihan gambar sumber tempat contoh disalin, contoh penyok, dan lokasi tempat contoh ini ditempel pada gambar target ditentukan secara acak. Dengan mengikuti pendekatan ini, kami menghasilkan set data pelatihan baru yang mencakup bercak ini. Gambar 2 menyajikan gambar contoh dengan penyok asli dan penyok yang ditambal setelah menerapkan augmentasi salin-tempel.

GAMBAR 2
Buka di penampil gambar
Presentasi PowerPoint
Contoh gambar (a) sebelum dan (b) sesudah penambahan patch.
3.5 Praproses Data dan Pengaturan Eksperimen
Berurusan dengan kumpulan data kecil berpotensi memengaruhi kinerja prediksi secara signifikan karena satu kesalahan prediksi tunggal mengubah total pengukuran. Dengan mengingat hal ini, kumpulan data asli dipartisi menjadi lima kumpulan data gambar sambil mempertahankan proporsi latih-uji 80%–20% yang diilustrasikan dalam Gambar 3. Dua puluh persen cacat dikeluarkan dan dipertahankan sebagai set pengujian, dan 80% sisanya membentuk set pelatihan di setiap partisi. Selanjutnya, kami melatih lima model, masing-masing pada partisi yang berbeda, dan menghitung AP pada masing-masing dari lima set pengujian. Hasilnya digunakan untuk membandingkan kinerja dua model deteksi relatif satu sama lain untuk setiap partisi kumpulan data.
GAMBAR 3
Buka di penampil gambar
Presentasi PowerPoint
Prosedur pengambilan sampel acak.
Jaringan Residual R-CNN yang Lebih Cepat dengan 101 lapisan (ResNet101) menggunakan model dasar COCO yang telah dilatih sebelumnya dalam Antarmuka Pemrograman Aplikasi (API) Deteksi Objek TensorFlow. Pengaturan konfigurasi yang digunakan dalam studi ini mencakup ukuran batch 4, laju pembelajaran 0,04, dan total langkah yang ditetapkan pada 13.000. Parameter lainnya dibiarkan pada nilai default, seperti yang diperoleh dari alur kerja TensorFlow untuk model tersebut. Model YOLOv8s dilatih selama 300 epoch dengan ukuran batch 16. Arsitektur tersebut telah dilatih sebelumnya menggunakan pembelajaran transfer pada kumpulan data COCO. Semua hiperparameter lainnya untuk melatih model YOLOv8s ditetapkan pada nilai default.
3.6 Evaluasi Model
Kinerja dievaluasi menggunakan akurasi dan AP dari Faster R-CNN dan YOLOv8. Kedua metrik dihitung berdasarkan nilai Intersection over Union (IoU) dari objek yang terdeteksi. IoU adalah rasio yang mengukur area interseksi antara kotak ground truth dan kotak prediksi, dibagi dengan area union dari kotak ground truth dan kotak prediksi untuk objek yang terdeteksi. Objek cacat diindikasikan jika IoU di atas 0,5 untuk perhitungan AP dan akurasi. Akurasi deteksi dihitung dengan menemukan rasio positif benar terhadap jumlah cacat sebenarnya. Metrik akurasi menilai kemampuan suatu metode untuk mendeteksi objek yang ada. Akurasi rata-rata kemudian ditentukan sebagai akurasi rata-rata di semua set, yang memberikan ukuran komprehensif dari kinerja keseluruhan. AP mengacu pada area di bawah kurva presisi dan recall. Metrik ini memungkinkan kita untuk menyeimbangkan trade-off antara prediksi yang benar dan mengidentifikasi contoh yang benar.
4 Hasil dan Pembahasan
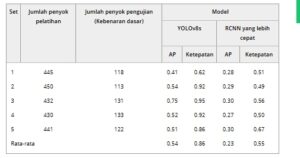
Menurut hasil pada Tabel 1 , YOLOv8s mengungguli Faster RCNN di masing-masing dari lima set (tanpa augmentasi data), mencapai AP rata-rata 0,54 dan akurasi rata-rata 0,86. Karena kinerja prediksinya yang lebih tinggi, YOLOv8s dipilih untuk evaluasi dua pendekatan augmentasi, yaitu salin-tempel dan augmentasi standar. Di antara lima set eksperimen pada Tabel 1 , set #1 menunjukkan kinerja terendah untuk kedua algoritma ML. Kinerja terendah terkait dengan memiliki lebih sedikit cacat dengan berbagai variasi pada set pengujian dan tidak cukup pada set pelatihan. Oleh karena itu, teknik salin-tempel dan augmentasi standar diterapkan untuk set #1 untuk meningkatkan jumlah cacat yang kurang terwakili dalam set pelatihan dan meningkatkan potensinya untuk peningkatan kinerja dibandingkan dengan set lainnya.
TABEL 1. Hasil evaluasi model deteksi objek.
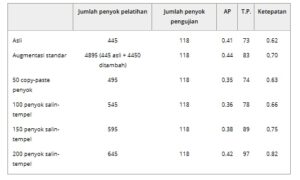
Tabel 2 menyajikan nilai AP, hitungan true positive (TP), dan tingkat akurasi set #1 untuk data asli (tanpa augmentasi) dan data augmentasi yang dihasilkan oleh teknik augmentasi standar dan salin-tempel. Pertama, augmentasi standar diterapkan pada setiap gambar dalam set pelatihan, yaitu, set data asli. Augmentasi standar meningkatkan AP dan tingkat akurasi masing-masing sebesar 8,00% dan 3,00%, dibandingkan dengan set data asli. Selanjutnya, metode salin-tempel yang dijelaskan dalam Bagian 3.4.2 diterapkan pada set data asli dengan secara bertahap meningkatkan jumlah cacat salin-tempel. Ketika 200 penyok salin-tempel disertakan, jumlah penyok yang terdeteksi meningkat dari 73 menjadi 97, menghasilkan peningkatan 20,00% dalam akurasi model. Sementara nilai AP meningkat secara proporsional dengan jumlah penyok salin-tempel, hanya ada peningkatan 1,00% dalam AP untuk 200 penyok salin-tempel dibandingkan dengan set asli #1. Salah satu faktor untuk stabilitas AP mungkin adalah penerapan strategi penambahan salin-tempel, yang dapat menyebabkan peningkatan TP tetapi tidak meningkatkan ketepatan kotak pembatas di sekitar cacat yang diprediksi. Artinya, metodologi salin-tempel dapat ditingkatkan dengan menggunakan teknik yang lebih kompleks untuk memilih cacat yang akan ditambah.
TABEL 2. Perbandingan teknik augmentasi pada set #1 menggunakan YOLOv8s.
Contoh hasil prediksi untuk set data asli, set data dengan penambahan standar, set data tambahan salin-tempel dengan 200 dent sintetis, dan kebenaran dasar disajikan dalam Gambar 4a–d , masing-masing. Set data asli menyertakan dent yang kurang terwakili dalam set pelatihan. Dengan menerapkan penambahan salin-tempel, jumlah dent yang kurang terwakili ditingkatkan dalam set pelatihan, sehingga meningkatkan deteksinya dalam set pengujian.

GAMBAR 4
Buka di penampil gambar
Presentasi PowerPoint
Prediksi penyok (a) tanpa penambahan, (b) dengan penambahan standar, (c) model dengan penambahan salin-tempel 200 kali, dan (d) kebenaran dasar.
5 Kesimpulan dan Rekomendasi
Studi ini mengevaluasi kinerja dua model deteksi objek pembelajaran mendalam, Faster R-CNN dan YOLOv8, untuk mendeteksi penyok di permukaan logam. Saat menilai kemampuan model pada data asli tanpa augmentasi, YOLOv8 mengungguli Faster R-CNN dengan AP rata-rata 0,54. Dua teknik augmentasi data digunakan untuk meningkatkan akurasi deteksi model YOLOv8. Dalam pendekatan pertama, augmentasi standar menggunakan empat teknik augmentasi: (i) pembalikan horizontal, (ii) pembalikan vertikal, (iii) transposisi, dan (iv) pemotongan tengah diterapkan pada setiap gambar dalam set pelatihan. Dalam pendekatan salin-tempel, penyok disalin dari gambar yang dipilih secara acak dan ditempel dengan mulus ke gambar lain dalam set pelatihan, memastikannya terintegrasi secara alami dengan latar belakang. Temuan kami menunjukkan bahwa sementara augmentasi standar menyebabkan peningkatan 8,00% dalam akurasi model, pendekatan salin-tempel meningkatkan akurasi model sebesar 20,00% dengan gambar yang jauh lebih sedikit. Kesimpulannya, teknik penambahan salin-tempel terbukti lebih efektif, mencapai akurasi yang lebih tinggi hanya dengan menambahkan 200 lekukan salin-tempel. Sebaliknya, metode penambahan standar memerlukan penambahan lebih dari 4000 lekukan dan peningkatan jumlah gambar sepuluh kali lipat, yang membutuhkan lebih banyak sumber daya komputasi. Efektivitas pendekatan salin-tempel menunjukkan bahwa lokasi lekukan yang ditambah mungkin memiliki dampak yang lebih besar pada akurasi daripada orientasi lekukan yang ditambah.
Dalam pekerjaan kami di masa mendatang, kami bermaksud untuk menyempurnakan pendekatan salin-tempel dengan meningkatkan ekstraksi dan integrasi fitur penyok. Pekerjaan kami di masa mendatang akan mengeksplorasi efek halus dari pendekatan ekstraksi dan penempelan penyok yang lebih canggih, seperti segmentasi cacat. Segmentasi cacat dapat menangkap fitur cacat dengan lebih akurat dan berpotensi menghasilkan deteksi penyok yang lebih andal.

